programming model
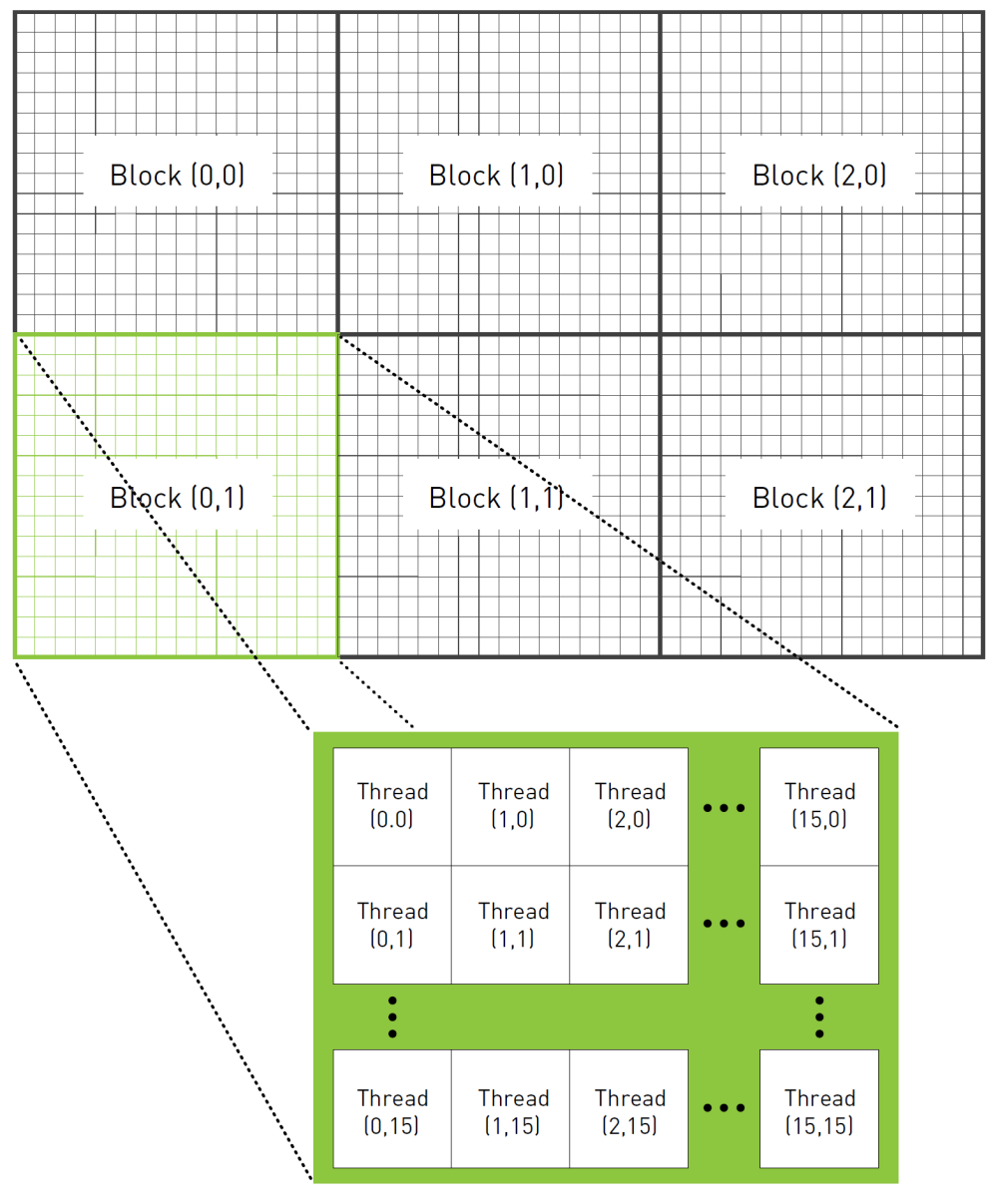
CUDA Programming: thread, block, grid
1
2
3
| dim3 blocks(3, 2);
dim3 threads(16, 16);
kernel<<<blocks, threads>>>(params, ...)
|
1
2
3
| int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
|
warp
1
2
| int tx= threadIdx.z *(blockDim.x*blockDim.y)+threadIdx.y*blockDim.x+threadIdx.x;
int warp_id=tx<<5;
|
thread model
cuda memory model
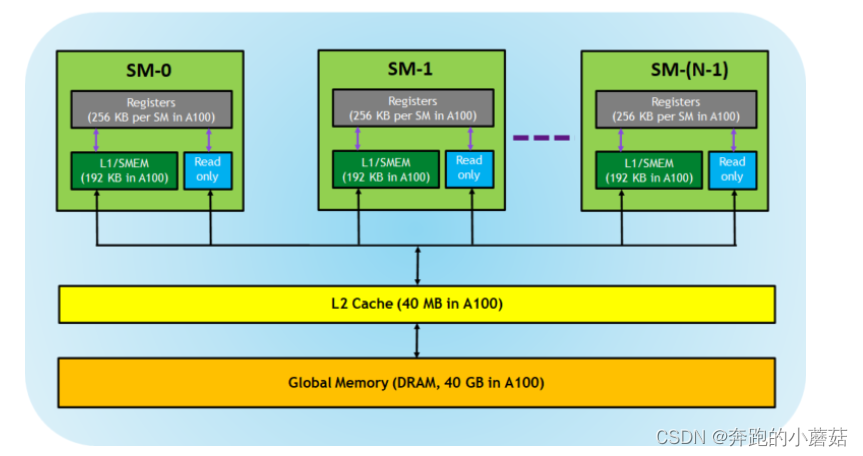
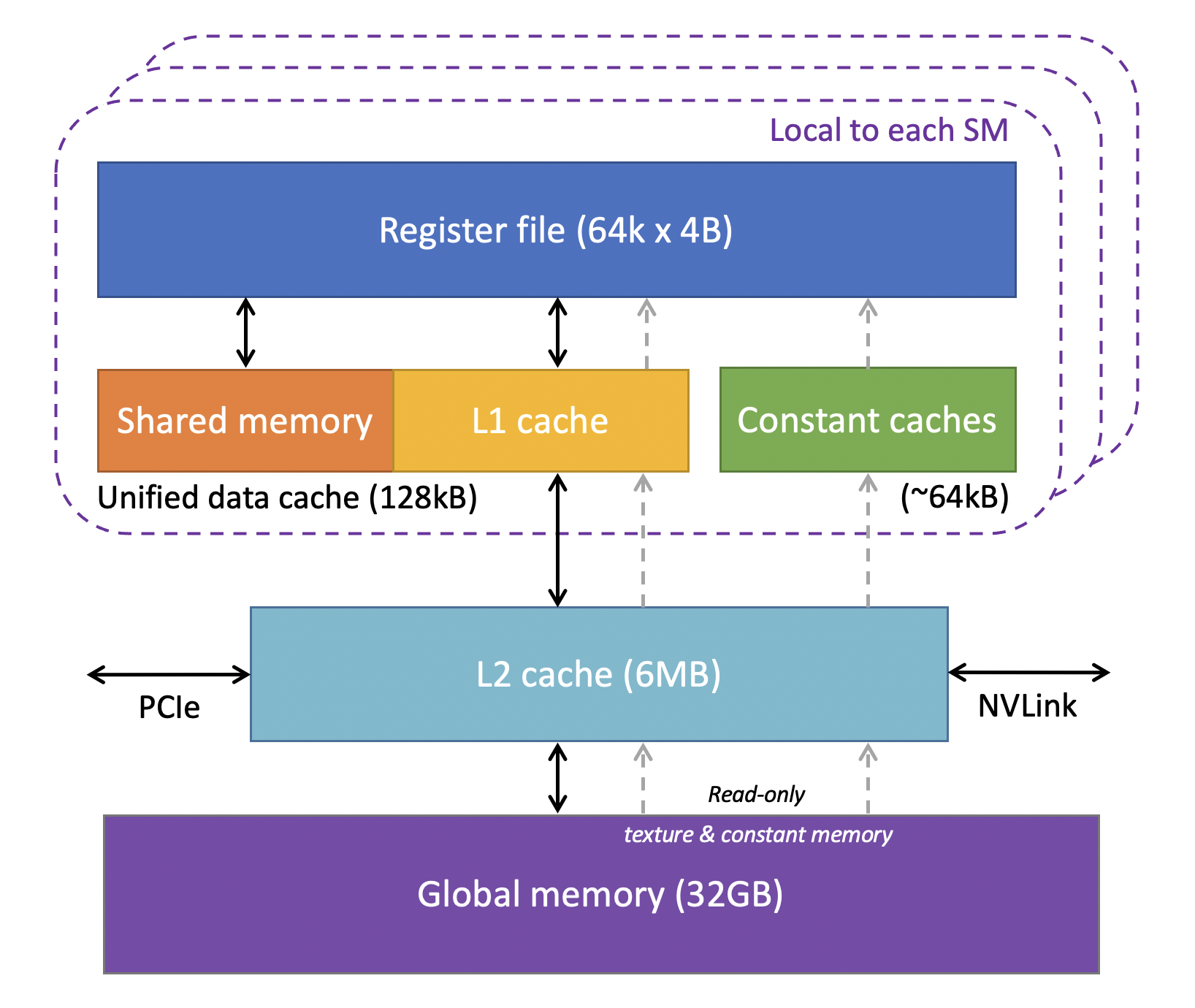
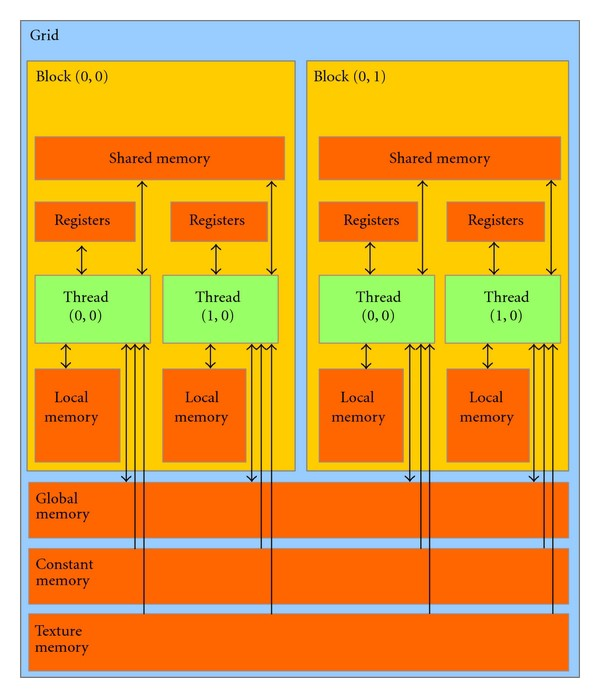
memory 分类
| 名称 |
位置 |
用途 |
使用方法 |
限制 |
备注 |
| Register寄存器 |
GPU的SM上 |
存储局部变量 |
|
每个SM上有成千上万个一个线程最大数量为256个需要省着用 |
线程私有,最快线程退出则失效 |
| Shared memory |
GPU芯片上 |
实现Block内的线程通信,目前最快的多Thread沟通的地方 |
__shared__修饰符需要__syncThreads()同步 |
分为32个banks需要省着用,会影响活动warp数量 |
可被1个block所有thread访问,次快高带宽,低延迟 |
| Local memory |
|
存放单线程的大型数组和变量(Register不够时用它) |
|
没有特定的存储单元 |
线程私有,速度较慢,速度与Global memory接近 |
| Constant memory常量内存 |
驻留在device memory中 |
用于同一warp的所有thread同时访问同样的常量数据,比如光线追踪 |
__constant__修饰符必须在host端使用 cudaMemcpyToSymbol初始化 |
没有特定的存储单元,但是有单独的缓存 |
只读,全局 |
| Global memory |
等同于GPU显存驻留在device memory中 |
输入数据,写入结果 |
|
|
全局,速度较慢 |
| Texture memory纹理内存 |
|
用于加速局部性访问,比如热传导模型 |
|
|
只读,全局,速度次于Shared Memory(延迟比Shared Memory高,带宽比hared Memory小) |
| Host memory:可分页内存 |
主机端内存 |
|
使用malloc访问使用free释放 |
不可以使用DMA访问 |
内存页可以置换到磁盘中 |
| 另一种Host memory:又称:Page-locked Memory,Zero-Copy Memory |
主机端内存 |
|
使用cudaMallocHost访问使用cudaFreeHost释放 |
|
属于另一种Global memory |

memory allocation
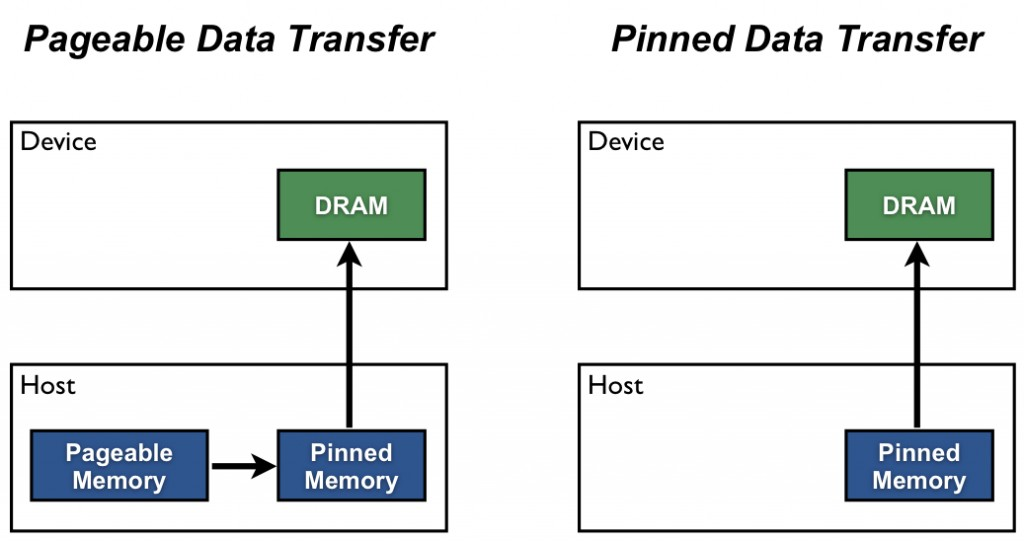
### pinned memory
1
2
3
| __host__ cudaError_t cudaHostAlloc ( void** pHost, size_t size, unsigned int flags)
__host__ cudaError_t cudaFreeHost ( void* ptr )
|
1
| cudaError_t cudaHostRegister (void * ptr, size_t size, unsigned int flags)
|
### reference
[CUDA Memory Access: Global, Zero-Copy, Unified](https://migocpp.wordpress.com/2018/06/08/cuda-memory-access-global-zero-copy-unified/)
CUDA Stream
不特别指定,runtime使用默认stream。CUDA 7之前,default stream是一个特殊的stream,能隐式同步设备上的其他stream。同一个stream中cuda命令是串行执行的。CUDA7开始,引入per-thread default streams,可以看作常规的流,有两个作用:(1)不同host线程有自己的default stream,能并发执行;(2)默认的流是常规的流。
cudaStreamSynchronize(stream) 用来进行流同步,会阻塞host线程。
cudaStreamQuery(stream) 用来检查指定流上所有操作是否都完成,不会阻塞host执行。
流创建
1
| __host__ cudaError_t cudaStreamCreate ( cudaStream_t* pStream )
|
1
| __host__ cudaError_t cudaStreamCreateWithFlags ( cudaStream_t* pStream , unsigned int flags )
|
创建不用标记的CUDA流。
- cudaStreamDefault 默认创建标记
- cudaStreamNonBlocking 创建非阻塞流,可以与流0(NULL)中工作同时进行,不会与流0执行隐式同步。
1
| __host__ cudaError_t cudaStreamCreateWithPriority ( cudaStream_t* pStream , unsigned int flags, int priority )
|
流销毁
1
| __host____device__ cudaError_t cudaStreamDestroy ( cudaStream_t stream )
|
流同步
1
| __host__ cudaError_t cudaStreamSynchronize ( cudaStream_t stream )
|