gpu code
https://github.com/Oramy/m2-cgpu
dl deploy
https://github.com/uber/neuropod
github
https://www.ruanyifeng.com/blog/2017/12/travis_ci_tutorial.html
gpu resource
- Arm Mali GPU Best Practices Developer Guide
https://developer.arm.com/documentation/101897/latest - Arm Mali Bifrost and Valhall OpenCL Developer Guide
https://developer.arm.com/documentation/101574/latest/
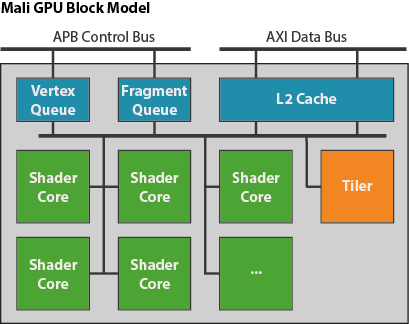
Midgard
write one 32-bit pixel per core per clock, 8-core design to have a total of 256-bits of memory bandwidth (for both read and write) per clock cycle
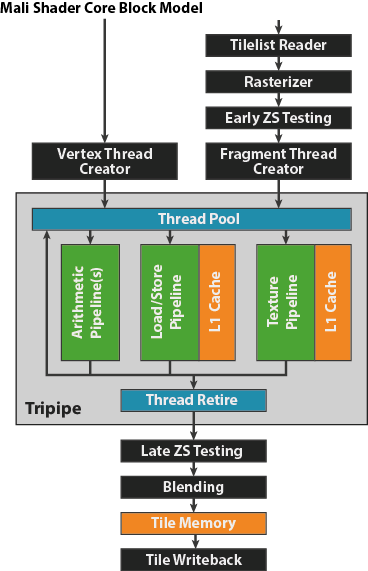
Tripipe design:
arithmetic pipeline
simd向量处理引擎,作用于128 bit 4字的寄存器,可以有多个,一般是每个shader core两个。能够弹性访问的数据类型包括2 x FP64, 4 x FP32, 8 x FP16, 2 x int64, 4 x int32, 8 x int16, or 16 x int8。
OpenCL kernels operating on 8-bit luminance data to process 16 pixels per SIMD unit per clock cycle。
For Mali T604 and T628, peak performance is 17 FP32 FLOPS per ALU per cycle.
flops instruction 7 dot product (4 Muls, 3 adds) 1 scalar add 4 vec4 add 4 vec4 multiply 1 scalar multiply Mali-T760:600MHz,16 cores, 浮点计算性能为326 FP32 GFLOPS, 16 * 600M * 2 * 17 FP32 FLOPS。包含两个arithmetic pipeline,17 FP32 FLOPS per pipeline per clock cycle。
load/store pipeline
texture pipeline.
texuture访存,bilinear filtering 一个时钟周期,trilinear filtering从两个不同mipmaps memory加载,需要两个时钟周期
memory system
每个shader core包含两个16KB L1 数据cache,分别用于texture和常规数据访问。
一个逻辑L2 cache,所有的shader core共享,由厂商来配置,通常每个实例shader core 32KB或者64KB。