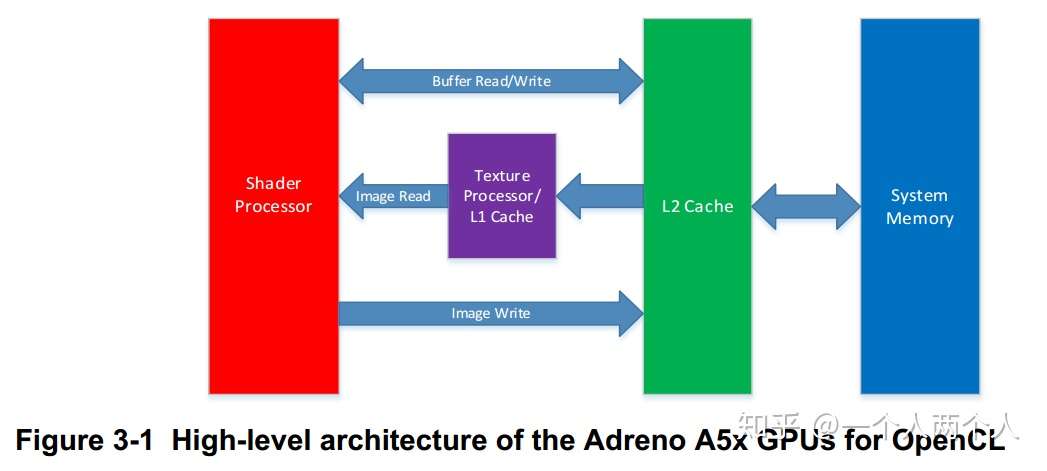
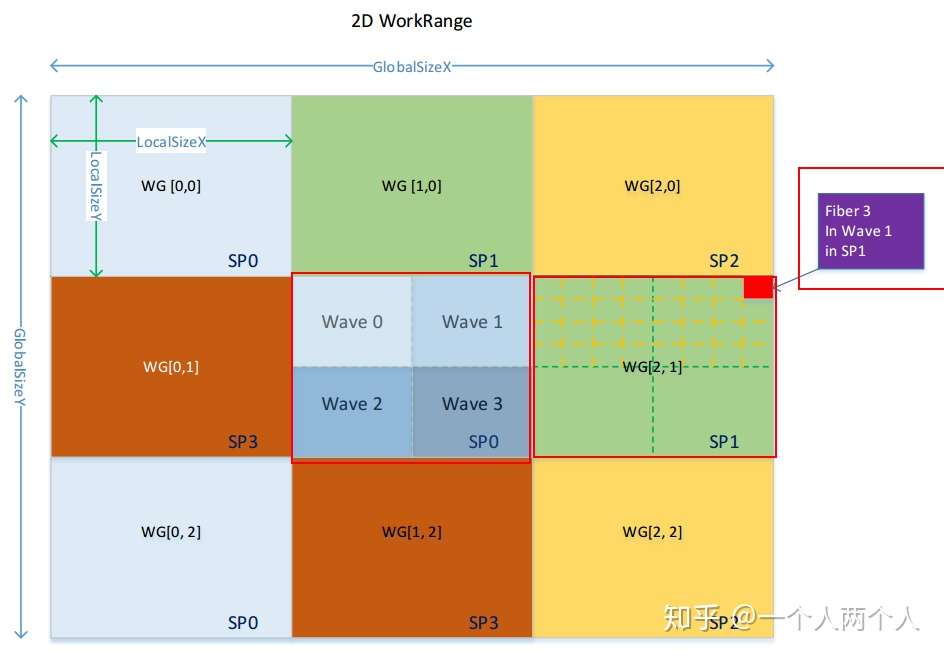
OpenCL平台模型
fiber(work item) - wave - workgroup
(thread - warp - block?)
OpenCL执行模型
上下文
命令队列
kernel执行
OpenCL存储器模型
存储类型
- host memory
- global memory
- constant memory
片内延迟低,系统RAM延迟高。work group中所有work item的常量数据。 - local memory
一个work group内的所有work item共享。
Local Memory coalesced access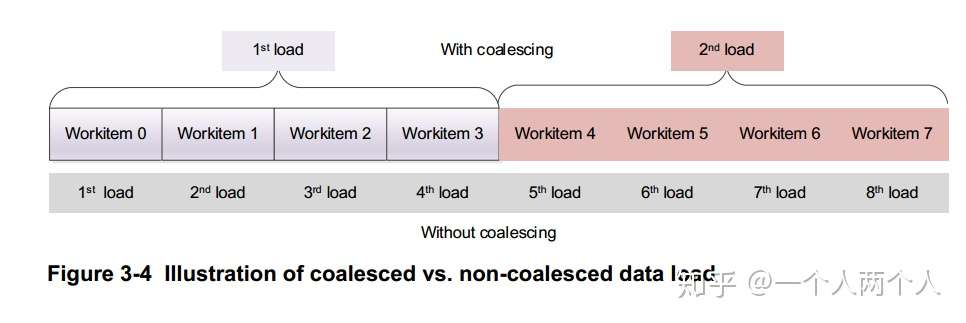
- private memory
存储对象类型
- buffer
- image
- pipe
OpenCL API
clCreateProgramWithSource()
clBuildProgram()
clLinkProgram()
clUnloadPlatformCompiler()
clCreateProgramWithBinary()
clCreate{Image|Buffer}
clEnqueueNDRangeKernel()
cl_mem clCreateBuffer (
cl_context context,
cl_mem_flags flags,
size_t size,
void *host_ptr,
cl_int *errcode_ret)
OpenCL性能优化
内存
- local memory
不同work item之间需要barrier进行同步,操作耗时。
不同work item之间交换数据需要barrier进行同步。
Barrier 经常会导致同步延迟,从而阻塞ALU,导致更低的ALU的使用效率。
在某些情况下,将数据缓冲到本地内存中可能会需要同步,同步产生的延迟将会抵消使用本地内存带来的性能提升。在这种情况下,直接使用全局内存,避免使用barrier可能是更好的选择。
OpenCL 资料
https://developer.qualcomm.com/download/adrenosdk/adreno-opencl-programming-guide.pdf
https://developer.qualcomm.com/sites/default/files/docs/adreno-gpu/developer-guide/gpu/gpu.html
https://developer.qualcomm.com/blog/matrix-multiply-adreno-gpus-part-1-opencl-optimization